
La généralisation des technologies IA multiplie les usages de la donnée en entreprise et accentuent l’importance des problématiques de traçabilité des données, de conformité réglementaire au RGPD et au respect des droits des personnes. Cependant, le développement et le déploiement de systèmes IA mettent aussi une pression supplémentaire sur la qualité des données au sein des organisations. Dans cet article, nous explorons l’articulation entre qualité des données et intelligence artificielle, et nous proposons aussi des méthodes pour améliorer la qualité des données à la source à l’aide de l’IA.
Données de qualité, de quoi parle-t-on ?
La norme ISO 8000 définit des données dites « de qualité » comme étant des données transférables qui répondent à des exigences spécifiées. Parmi ces exigences, on peut noter :
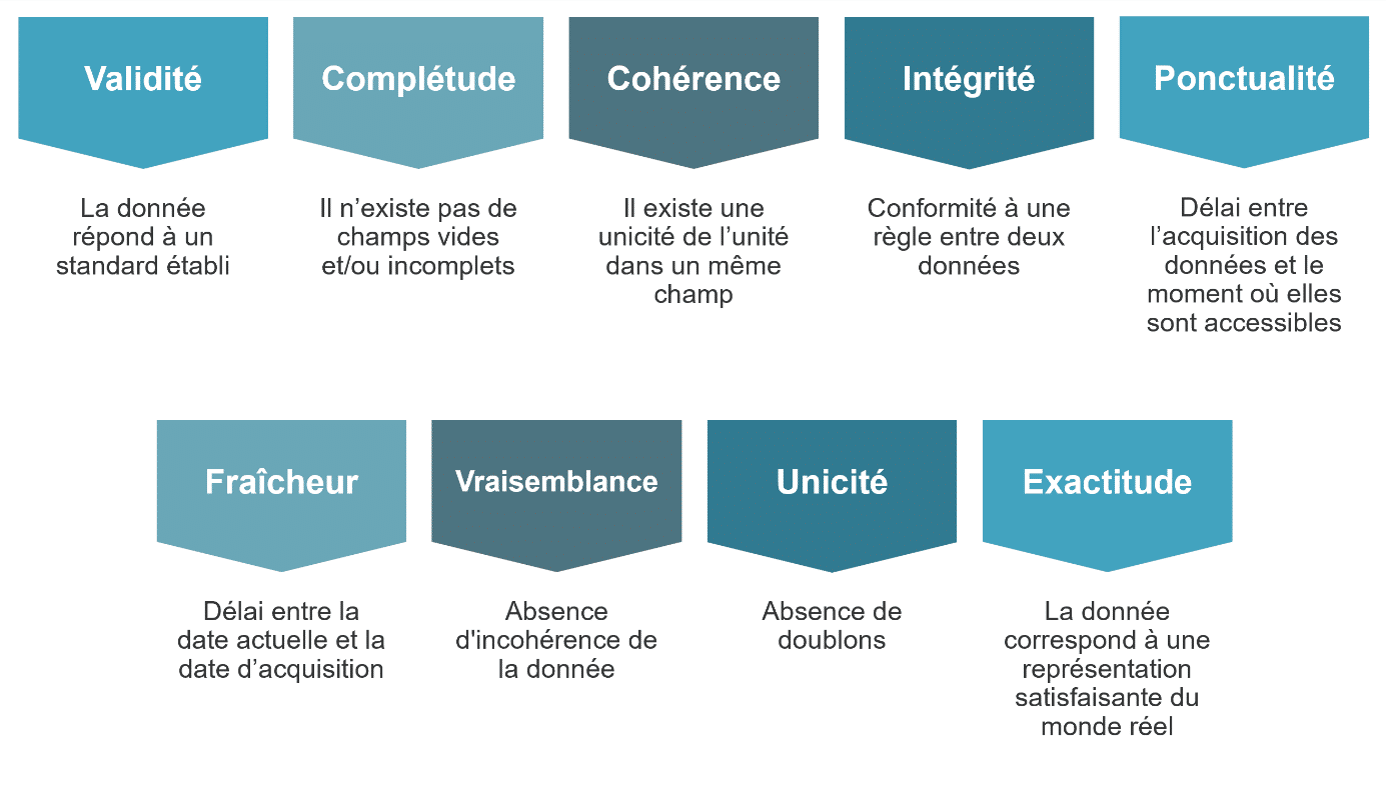
Ces principes permettent de délimiter ce qu’on considère comme étant une « donnée de qualité » et assurent ainsi la fiabilité, l’exhaustivité et la précision de la donnée sur l’ensemble de son cycle de vie : de sa collecte au maintien de sa qualité en phase de transformation, jusqu’à son interprétation en sortie.
La qualité des données a un impact direct sur le déroulement des processus opérationnels. En effet, des données incorrectes ou incomplètes, des doublons, des formats incohérents…, sont autant d’anomalies qui peuvent mener à :
- des décisions inadaptées,
- des pertes de revenus et d’opportunités,
- un impact sur l’image de marque,
- des risques juridiques
L’importance d’une donnée de qualité ne fait pas de débat au sein des entreprises. Malgré cela, on observe très peu de politiques dédiées à l’évaluation de la qualité des données et à la mise en place de processus standardisés liés de labellisation ou de contrôle continu de la qualité des données. Si le sujet n’est pas tiré par un régulateur, comme par exemple pour la régulation BCBS 239 portant sur les données de risques, il est rarement priorisé par les organisations.
Parmi les freins à la mise en place de telles politiques Data Quality, on peut citer par exemple le manque d’attention et/ou de moyens accordés aux questions Data au sein des organisations, mais également des infrastructures IT vieillissantes, une répartition floue des rôles et responsabilités entre les acteurs (ex. IT vs métiers) ou encore une fragmentation des données qui sont présentes et/ou dupliquées dans plusieurs systèmes indépendants les uns des autres… Avant l’explosion de l’IA, une étude commissionnée en 2019 par l’éditeur de logiciel BlackLine, 70 % des organisations ont déjà pris une décision importante sur la base de données inexactes.
Des prises de conscience ont néanmoins eu lieu sur ces questions face à l’accroissement du volume de données utilisées ainsi que la diversification des usages, mais nous sommes encore loin du compte…
L’IA est un usage consommateur de données de qualité
Au-delà des besoins intrinsèques de l’entreprise (ex. KYC ou CRM) et des exigences réglementaires sur la maitrise de ces données (ex. impact RGPD), l’IA est en grande partie la cause des récentes initiatives d’amélioration de la qualité des données.
En effet, lorsqu’on traite des données à des fins commerciales et/ou dans le cadre de toute autre activité à l’aide des technologies IA, il est nécessaire de s’assurer que les données de base (input) sont correctes, exhaustives, à jour… pour s’assurer que les données en sortie (output) soient exploitables et répondent bien aux attendus fixés.
Selon une étude de l’entreprise Informatica en 2025, seules 33% des entreprises ont pu convertir plus de la moitié de leurs pilotes d’IA générative en production. Les difficultés sont attribuées principalement à la qualité ou disponibilité des données, ou au manque de maturité technologique. Les résultats obtenus avec ces systèmes d’IA deviennent peu fiables en conditions réelles, réduisant ainsi à néant une partie des investissements réalisés par les entreprises dans ce domaine.
Quand il s’agit d’IA, que ce soit sur des données structurées pour construire des modèles prévisionnels et/ou de scoring, ou des données non-structurées (ex. documentation interne de l’entreprise) pour construire des RAG ou agents spécialisés, si les données d’entrée sont jugées incorrectes, défectueuses ou absurdes (on parle de « garbage in ») les données de sortie seront nécessairement absurdes (« garbage out »). Cela peut notamment conduire à des prises de décisions inadaptées : c’est donc un réel enjeu qui couvre bien plus que la seule dimension technique/data.
Selon une étude menée par l’éditeur de la plateforme de données Fivetran, les entreprises perdent 6% de leur chiffre d’affaires annuel global, soit 406 millions de dollars, à cause de modèles d’IA défectueux car basés sur des données de mauvaise qualité. Au-delà des simples erreurs, cela peut avoir des conséquences juridiques importantes ainsi que des implications au niveau éthique (discrimination, biais…) pouvant ainsi impacter l’image de l’entreprise et sa pérennité.
D’autant que les entreprises disposent d’une vraie mine d’or grâce aux bases de connaissances internes, qui sont actuellement loin d’être exploitées en raison des mauvaises pratiques : duplicatas, gestion disparate, manque de structuration des bases de données… On pourrait parler de « nouvel or noir » pour les entreprises, à condition d’avoir une gestion structurée et normalisée de la donnée pour pouvoir l’exploiter…
L’IA peut aussi optimiser la qualité des données
L’IA peut améliorer la qualité des données : détection d’anomalies, identification de doublons, nettoyage automatique, contrôles de cohérence, etc., grâce notamment à l’automatisation des vérifications et des procédures de correction. Si on prenait donc le problème dans l’autre sens, il pourrait être envisagé de faire appel à l’IA afin d’assurer la qualité des données (en input) qui permettraient d’utiliser des données dites « de qualité » dans les modèles et ainsi de générer des résultats pertinents (en output).
L’IA peut automatiquement détecter des erreurs en identifiant les doublons ou en détectant les incohérences de format au sein d’un jeu de données. Il est également possible d’entrainer un modèle sur des données contrôlées au préalable afin qu’il puisse détecter des valeurs aberrantes. On peut enfin détecter en temps réel les dégradations de cohérences de nos données (perte de complétude des champs, dérive statistique de l’ensemble des données…) au fil du temps ou le long du data pipeline entre la donnée source et l’information restituée aux utilisateurs finaux.
On voit donc qu’il est possible d’articuler les chantiers de qualité des données et d’IA dans un cercle vertueux d’amélioration continue. Cependant, pour arriver à cette double articulation les entreprises doivent se construire une vision claire des enjeux liés à la qualité des données, mais également des répercussions de ces chantiers pour les métiers producteurs et utilisateurs de la donnée.
Cela suppose d’adopter une approche holistique de la donnée et de ses challenges et d’inscrire ces chantiers dans un schéma directeur Data. Une démarche vertueuse, mais qui repousse bien souvent les projets à des horizons très éloignés, qui multiplie les acteurs impliqués et complexifie encore un peu plus les problématiques Data… Comment rester pragmatique tout en adressant ces questions stratégiques ?
Quelques actions quick-wins pour maîtriser ses données de bout en bout
Chez AMITA, nous aidons les organisations à transformer leurs données en actifs fiables et exploitables. Notre approche couvre tout le cycle de vie de la donnée – de la collecte à l’archivage – avec trois objectifs : sécuriser la conformité réglementaire, fiabiliser les usages de l’IA et maximiser la valeur métier.
Notre démarche accompagne les entreprises à formaliser le pilotage de leurs cas d’usage Data & IA, afin d’assurer une couverture de l’ensemble des besoins et de garantir une gestion de la donnée qui soit non seulement utile, mais souhaitable en termes humains et éthiques :
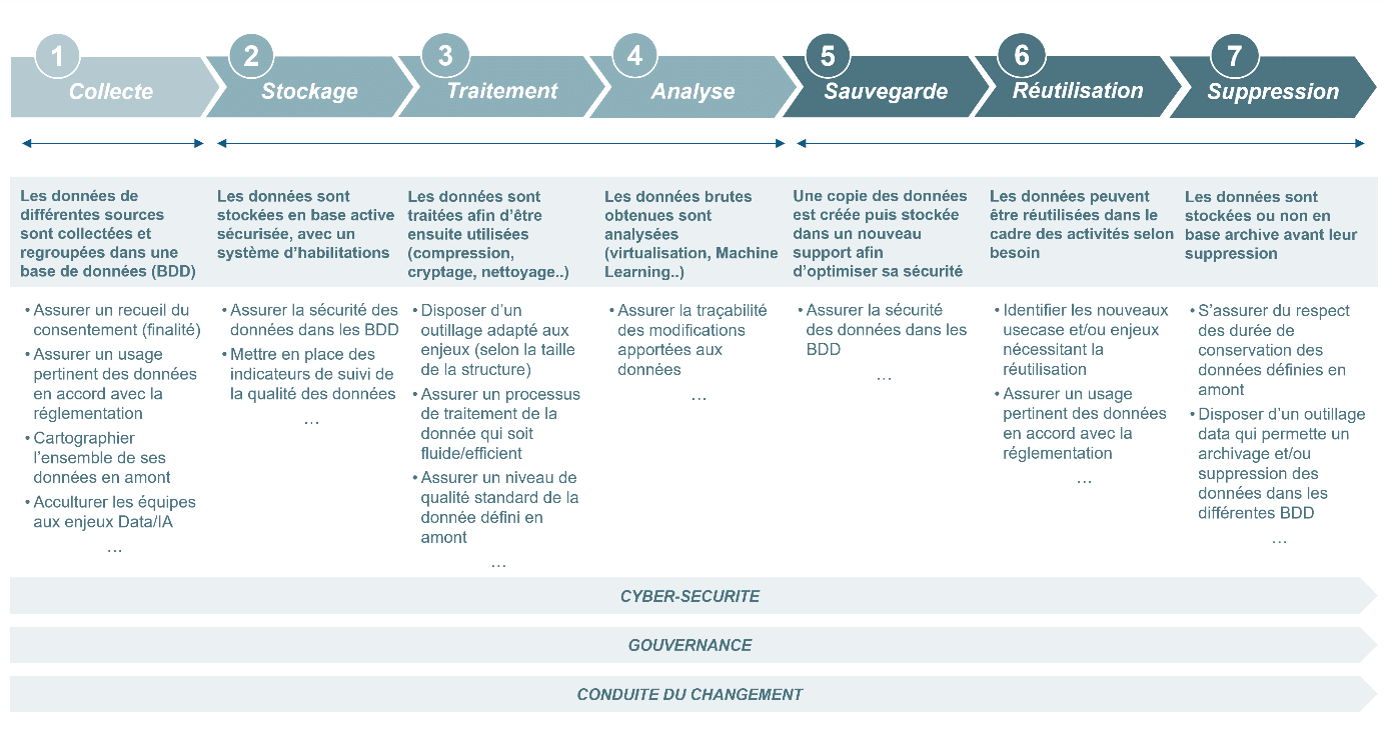
En complément du pilotage du portefeuille de cas d’usages Data & IA, vous trouverez ci-dessous quelques exemples d’actions quick-wins réalisées auprès de nos partenaires pour améliorer la qualité des données :
- Cartographier l’ensemble de ses données en amont : Il est tout d’abord nécessaire de pouvoir cartographier les types de données collectées et traitées, ainsi que les usages qui en sont fait, leur lieu de stockage… Cela peut par exemple passer par un recensement des métadonnées ou la mise en œuvre d’un dictionnaire de données (logiciel) permettant notamment d’améliorer la scalabilité des données et les flux mais également d’éviter la duplication de la donnée (doublons) dans les systèmes.
- Auditer la sécurité des données tout au long de la chaîne de valeur : Après avoir cartographié ses données, il est nécessaire de s’assurer qu’elles soient stockées sur des espaces sécurisés (Cloud ou on-premise) ainsi que de la mise en œuvre de mesures de cybersécurité afin d’éviter par ex. le piratage ou la diffusion de données personnelles. Un audit régulier des systèmes d’information ainsi que des dispositifs de sécurité est donc requis pour évaluer la robustesse aux cyber risques et tenir à jour les politiques de sécurité.
- Mettre en place des indicateurs de suivi de la qualité des données : La mise en place d’indicateurs reflétant le niveau de qualité des données permet de suivre la qualité des données durant tout le cycle de vie, de la collecte à la suppression des données, afin d’éviter l’utilisation de données « de mauvaise qualité » en amont qui pourraient impacter les usages en aval.
- Clarifier la gouvernance de la donnée : C’est un axe essentiel compte tenu des enjeux identifiés précédemment : définir les rôles et responsabilités de chacun des acteurs ainsi que leur périmètre d’intervention, mettre en œuvre des dispositifs de contrôle tout au long du cycle de vie des données, etc. Nous accompagnons les organisations dans la mise en œuvre d’une gouvernance Data à travers la définition/structuration des process (RACI), et la rédaction des normes et politiques internes associées. Tous ces éléments permettent ainsi d’avoir un cadre partagé et commun au sein de l’organisation.
- Acculturer les équipes aux enjeux Data-IA : Il est crucial d’acculturer les acteurs au sein de l’organisation aux enjeux Data-IA et de diffuser des « bonnes pratiques » afin d’assurer une utilisation adéquate des données au niveau métiers/réglementaire ainsi que le respect des principes clés. La qualité des données doit ainsi devenir une vraie « culture d’entreprise ». Nous pouvons animer des séminaires de sensibilisation des équipes SI et métiers, mais aussi co-construire avec vous un plan de communication et de formation des collaborateurs.
- Benchmarker son SI au regard des enjeux Data : Il peut par ailleurs être nécessaire pour la DSI d’établir un nouveau contrat de service avec ses clients internes, pour s’assurer que les outils techniques sont toujours en adéquation avec les besoins des métiers. AMITA Conseil peut accompagner les DSI sur tous ces aspects, de la réalisation d’un simple benchmark à l’étude de l’adéquation entre les fonctionnalités de SI et la stratégie de l’entreprise. Ces travaux peuvent ensuite donner lieu à la réalisation d’un Schéma Directeur SI Data, au développement de nouveaux outils Data Science (Make), ou à se rapprocher d’acteurs spécialisés pour intégrer leurs solutions (Buy).
En conclusion, sans données de qualité, pas d’IA fiable ni durable. La réussite du déploiement des modèles d’IA passer forcément par des données de qualité, et les enjeux dépassent la simple dimension technique : ils sont réglementaires, business et même éthiques. Plutôt que d’opposer ces deux problématiques, nous avons fait le choix chez AMITA de les allier pour vous proposer des actions concrètes permettant de transformer vos données en leviers de performance durable.
Les auteurs :
Adrien Pina
Manager
Julia Snidaro
Consultante Sénior
Pierre-Antoine Andrighetti
Consultant


